
Automatic Image Captioning System
Automatic Image Captioning System brings together the realms of computer vision and natural language processing to allow machines not just to see images, but to describe them in natural language. At the heart of the system lies an encoder-decoder architecture: a Convolutional Neural Network (CNN) pre-trained on large-scale datasets serves as the encoder, extracting nuanced visual features, while a Long Short-Term Memory (LSTM) network acts as the decoder, generating coherent captions word by word. Inspired by the seminal “Show and Tell: A Neural Image Caption Generator” paper, this implementation follows a proven yet adaptable model, designed to take an input image and produce a descriptive sentence that captures its content. The repository is structured thoughtfully: you’ll find Jupyter notebooks for training and experimentation, a well-organized Conda environment setup (environment.yml), scripts for model training (train_utils.py), data handling (data.py, utils.py), and a tracking framework using Weights & Biases and Ax for hyperparameter tuning.
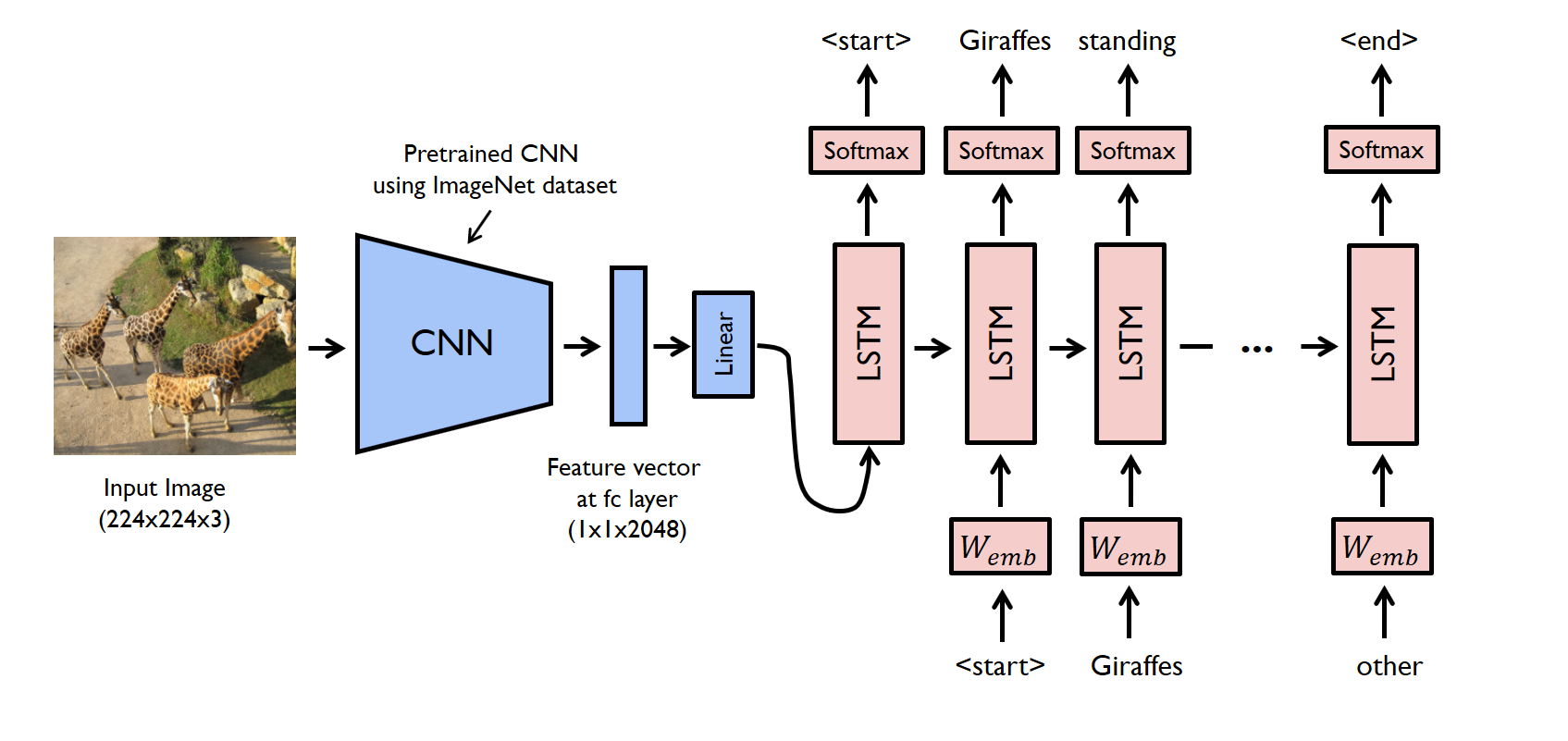
The captioning pipeline begins with preparing the Flickr8k dataset, one of the classic image-caption datasets, organizing image files and paired captions into training, validation, and test splits. During training, the CNN encoder transforms each image into a compact and informative feature vector, which the LSTM receives at the start of a sequence generation process. The decoder then iteratively builds a sentence, conditioned on both these features and the previously generated words. A suite of hyperparameters (learning rate, embedding dimensions, LSTM layers) is tuned via Ax and the training process tracked using Weights & Biases, providing transparency and reproducibility. According to the README, while the original paper reports a BLEU score of 27.2, this model achieves a modest, but valuable, BLEU score of around 11 on its test split, indicating the system generates captions with reasonable fidelity, especially considering domain differences in training data. Model speed is also noted: after initial loading, caption generation takes around 5 seconds per image, making the system practical for demo or prototype use.
The value of this project lies in its technical implementation and also in its accessibility, modularity, and potential for expansion. Packaged under an MIT license, it’s primed for experimentation. Researchers can swap in upgraded encoders (like Transformer-based vision models), tune LSTM parameters, or expand to richer datasets like MS COCO to improve performance. Its documentation and notebook-based approach make it educational as well as practical, perfect for users exploring image–language models from end to end. Potential extensions include adding attention mechanisms (Show, Attend, and Tell), beam search for more fluent captions, or even transformer decoder architectures for better sequence modeling. In real-world terms, this pipeline could power accessibility tools that describe images for visually impaired users, automate content tagging for image databases, or empower developers with plug-and-play visual understanding modules. This project stands out as a robust foundation in image captioning, both a learning tool and a launch pad for richer, more capable systems.

Faculty
-
Dr. Muhammad Moazam FrazDr. Muhammad Moazam Fraz
Students
-
Muhammad Abdullah
-
Usama Athar