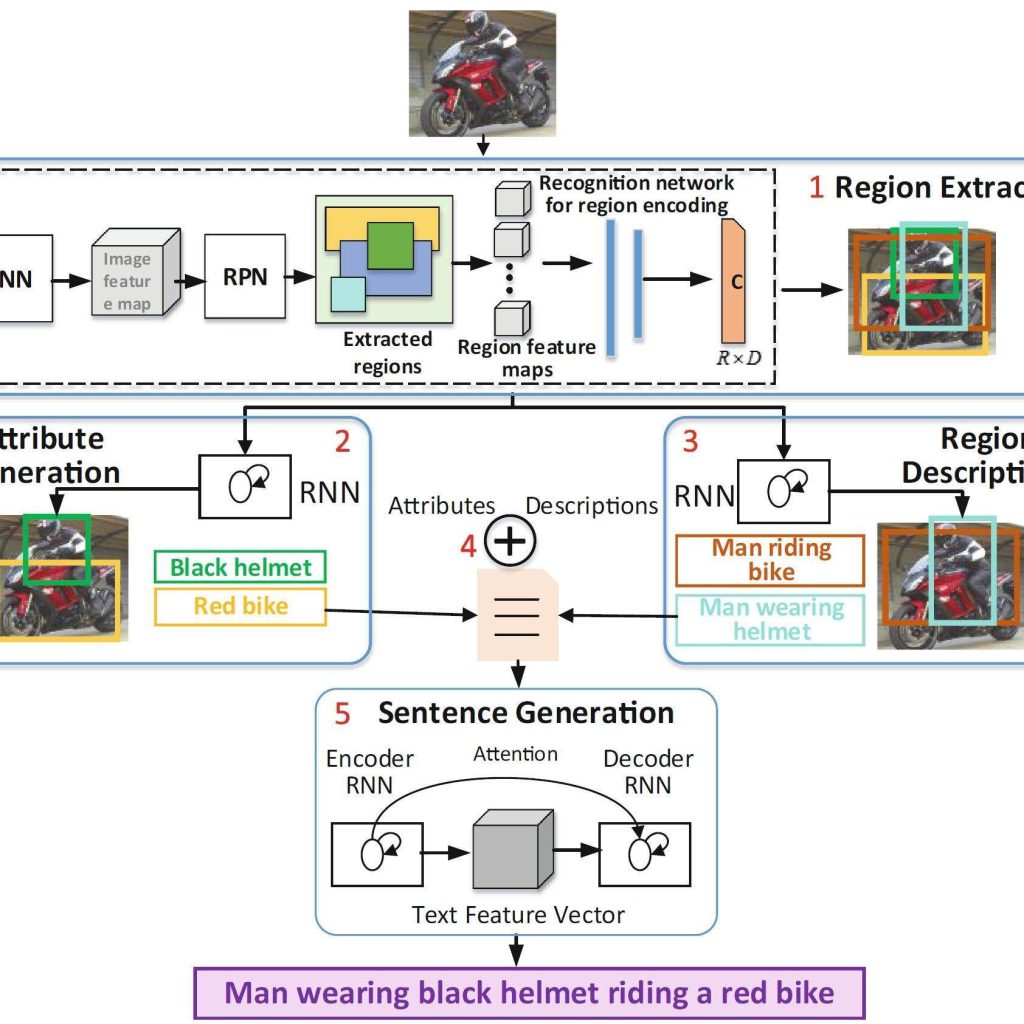
Model overview. Region extraction module extracts object regions. These regions are converted into region descriptions and object attributes. Sentence Generation block then joins all region descriptions and attributes to form a detailed sentence
I Khurram, M.M. Fraz , M Shahzad, NM Rajpoot , “Dense-CaptionNet: A Sentence Generation Architecture for Fine-Grained Description of Image Semantics”, Cognitive Computing, Vol. 12 , No. 2, PP. 1-31, Mar, 2020. IF: 4.287
I Khurram, M M Fraz, M Shahzad , , “Detailed Sentence Generation Architecture for Image Semantics Description”, Proceedings of the 13th International Symposium on Visual Computing, Nov, 2018, Las Vegas, United States.