

Large networks of cameras are increasingly deployed in public places like airports, railway stations, college campuses and office buildings. These cameras typically span large geospatial areas and have non-overlapping fields-of-views (FOVs) to provide enhanced coverage. Such networks provide huge amounts of video data, which is either manually monitored by law enforcement officers or utilized after the fact for forensic purposes. Human monitoring of these videos is erroneous, time consuming and expensive, thereby severely reducing the effectiveness of surveillance. Automated analysis of large amounts of video data can not only process the data faster but significantly improve the quality of surveillance. Video analysis can enable long term activity and behavior characterization of people in a scene. Such analysis is required for high-level surveillance tasks like suspicious activity detection or undesirable event prediction for timely alerts to security personnel making surveillance more pro-active.
Understanding of a surveillance scene through computer vision requires the ability to track people across multiple cameras, perform crowd movement analysis and activity detection. Tracking people across multiple cameras is essential for wide area scene analytics and person re-identification is a fundamental aspect of multi-camera tracking. Re-identification (Re-ID) is defined as a process of establishing correspondence between images of a person taken from different cameras. It is used to determine whether instances captured by different cameras belong to the same person, in other words, assign a stable ID to different instances of the person.

In an Intelligent traffic monitoring system vehicle re-id plays an import role as vehicle re-id is a process in which we are going to detect a vehicle and then re-identify the vehicle from our database of vehicles. This can play an important role in the field of live monitoring or tracking the vehicles or doing forensic analysis like finding patterns of different vehicles etc. This requires intelligent and efficient algorithms and to solve this problem, we will be using the deep learning which is state of the art for many problems these days.
The vehicles will be from the surveillance camera using state of the art deep learning detectors like SSD or YOLO and then on top of that given a vehicle image, to search in a database for images that contain the same vehicles captured by multiple cameras for re-id purpose using the state of the art deep learning techniques like Siamese neural network, RNN and temporal reasoning algorithms.
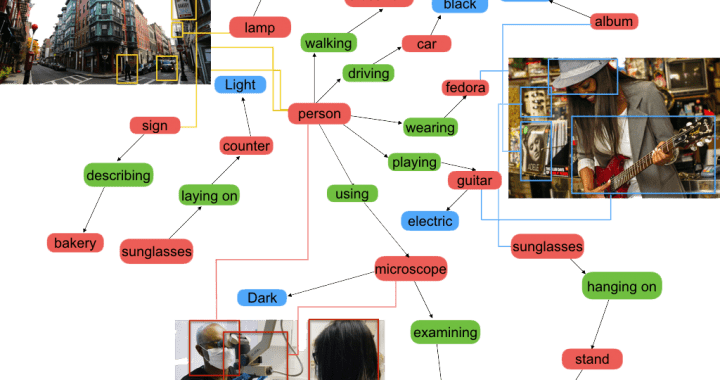
To develop a model/framework that generates natural language descriptions of images and their regions. A quick glance at an image is sufficient for a human to point out and describe an immense amount of details about the visual scene. However, this remarkable ability has proven to be an elusive task for our visual recognition models. We are working to develop methodology for automated image description and captioning using the combination of linguistic and visual information with the aim of better image understanding and visual recognition.
Imagine this kind of technology being refined and expanded to surveillance systems. (“A car running over a human”, followed by a notification for review of the footage by humans).
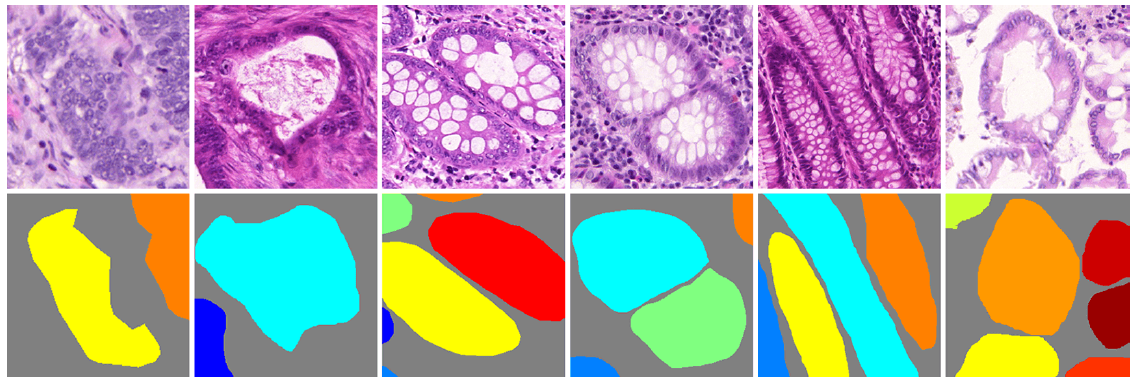
To make reliable diagnosis, pathologists often need to identify certain special regions in medical images. In cancer diagnosis via histology tissue image examination, muscle regions are known to have no immune cell infiltration, and thus are ignored by pathologists. Other clinically diagnostic region of interests are;
The analysis of glandular morphology within colon histopathology images is an important step in determining the grade of colon cancer. Despite the importance of this task, manual segmentation is laborious, time-consuming and can suffer from subjectivity among pathologists. This task is non-trivial due to the large variability in glandular appearance and the difficulty in differentiating between certain glandular and non-glandular histological structures.
The proposition is to use Deep Neural Networks for segmentation of clinically significant regions. The performance will be evaluated on publicly available data-sets.

Web: http://acdc-lunghp.grand-challenge.org
Digital pathology has been gradually introduced in clinical practice. Although the digital pathology scanner could give very high resolution whole-slide images (WSI) (up to 160nm per pixel), the manual analysis of WSI is still a time-consuming task for the pathologists. Automatic analysis algorithms offer a way to reduce the burden for pathologists. Our proposed challenge will focus on automatic detection and classification of lung cancer using Whole-slide Histopathology. This subject is highly clinical relevant because lung cancer is the top cause of cancer-related death in the world.
Patch based cancer image classification

Web: https://github.com/basveeling/pcam , https://patchcamelyon.grand-challenge.org/Introduction/
Fundamental machine learning advancements are predominantly evaluated on straight-forward natural-image classification datasets. Think MNIST, CIFAR, SVHN. Medical imaging is becoming one of the major applications of ML and we believe it deserves a spot on the list of go-to ML datasets. Both to challenge future work, and to steer developments into directions that are beneficial for this domain.
PCam benchmark dataset can play a role in this. It packs the clinically-relevant task of metastasis detection into a straight-forward binary image classification task, akin to CIFAR-10 and MNIST. Models can easily be trained on a single GPU in a couple hours, and achieve competitive scores in the Camelyon16 tasks of tumor detection and WSI diagnosis. Furthermore, the balance between task-difficulty and tractability makes it a prime suspect for fundamental machine learning research on topics as active learning, model uncertainty and explainability.

Web: http://spiechallenges.cloudapp.net/competitions/14
A cancer cellularity scoring challenge for tumor burden assessment in breast pathology is proposed. The aim is to develop an automated method for analyzing histology patches extracted from whole slide images and assign a score reflecting cancer cellularity in each. Currently, this task is performed manually and relies upon expert interpretation of complex tissue structures. Furthermore, reproducibility of cancer cellularity scores is a concern in current practice, therefore a fully automated method holds great promise for increasing throughput and reducing inter- and intra-observer variability.
Digestive-System Pathological Detection and Segmentation

Web: https://digestpath2019.grand-challenge.org/
Examination of pathological images is the golden standard for diagnosing and screening cancers in the digestive system. Digital pathology has become increasingly popular in recent years and allows examination of high-resolution whole image (WSI) in remote locations. Such a functionality is convenient for hospitals in rural areas of developing countries, where there are not enough experienced pathologists for accurate diagnosis. However, manual analysis of WSI is still a time-consuming task for the pathologists because the WSI can be up to size 100,000 X 100,000 pixels. This prevents remote examination to be widely adopted in developing countries/regions where there are not enough pathologists. One promising solution is to develop medical models to automatically detect, segment, and classify cells of interests in different pathological images. Such problems attract much attention from the medical imaging community and there is a larger number of existing papers on pathological image segmentation.
Classification of Normal vs Malignant Cells in B-ALL White Blood Cancer Microscopic Images
![]()
Web : Link
Relevance of the Problem
Cell classification via image processing has recently gained interest from the point of view of building computer assisted diagnostic tools for blood disorders such as leukemia. In order to arrive at conclusive decision on disease diagnosis and degree of progression, it is very important to identify malignant cells with high accuracy. Computer assisted tools can be very helpful in automating the process of cell segmentation and identification. Identification of maIignant cells vis-à-vis normal cells from the microscopic images is difficult because morphologically both cells types appear similar.
As a consequence, leukemia (blood cancer) is detected in advanced cancer stages via microscopic image analysis, not because of the ability to identify these under the microscope, but because of the medical domain knowledge, i.e., the cancer cells start growing in an unrestricted fashion and hence, they are present in much more larger numbers as compared to their numbers in a normal person.
It is, however, important to do early disease diagnosis for better cure and for improving the overall survival of the subjects suffering with cancer. Although advanced methods such as flow cytometry are available, they are very expensive and are not available widely in pathology laboratories or hospitals, particularly, in rural areas. On the other hand, a computer based solution can be deployed easily at a much lesser cost. It is hypothesized that advanced methods of medical image processing can lead to the identification of normal versus malignant cells and hence, can aid in the diagnosis of cancer in a cost effective manner.
Hence, this is an effort to build an automated classifier that will overcome the problems associated with deploying sophisticated high-end machines with recurring reagent cost. It will also aid pathologists and oncologists to make quicker and data driven inferences.
Aim:
Classification of leukemic B-lymphoblast cells from normal B-lymphoid precursors from blood smear microscopic images.
In this challenge, a dataset of cells with labels (normal versus malignant) will be provided to train machine learning based classifier to identify normal cells from leukemic blasts (malignant cells). These cells have been segmented from the images after those images have been stain normalized. The overall size of the images were 2560×1920, while a single cell image is roughly of the size of 300×300 pixels. The images are representative of images in the real-world because these contain some staining noise and illumination errors, although these errors have largely been fixed by us via our own inhouse method on stain normalization [1,2].
The ground truth has been marked by the expert oncologist. The aim of the challenge is to compare and rank the different competing methods developed by participants based on the performance metrics such as accuracy and F1 scores.
Who would like to work on this problem?
This problem is challenging because as stated above, morphologically, the two cell types appear very similar. The ground truth has been marked by the expert based on the domain knowledge. Also, with our efforts in the past two years, we have also recognized that the subject level variability also plays a key role and as a consequence, it is challenging to build a classifier that can yield good results on prospective data. Anyone deeply interested in working on a challenging problem of medical image classification via building newer deep learning/machine learning architectures would, in our opinion, come forward to work on this challenge.
References and credits:
[1] Anubha Gupta, Rahul Duggal, Ritu Gupta, Lalit Kumar, Nisarg Thakkar, and Devprakash Satpathy, “GCTI-SN: Geometry-Inspired Chemical and Tissue Invariant Stain Normalization of Microscopic Medical Images,” under review.
[2] Ritu Gupta, Pramit Mallick, Rahul Duggal, Anubha Gupta, and Ojaswa Sharma, “Stain Color Normalization and Segmentation of Plasma Cells in Microscopic Images as a Prelude to Development of Computer Assisted Automated Disease Diagnostic Tool in Multiple Myeloma,” 16th International Myeloma Workshop (IMW), India, March 2017.